OP
- Messages
- 7,659
- Reaction score
- 4,720
- # of dives
- 200 - 499
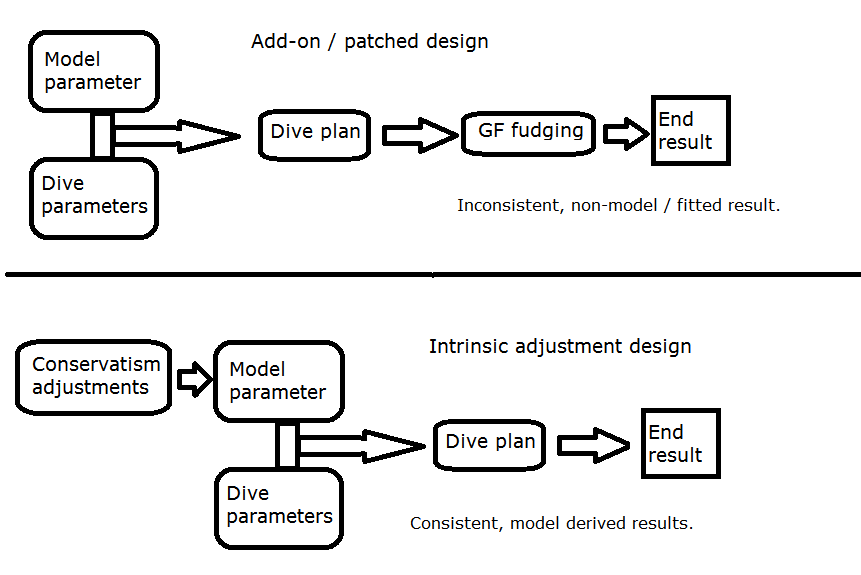
Well yeah. If you start adding conservatism then you deviate from the model on the side of caution. A little bit of deviation is fine, but things go sour fast. You may find that you are doing an awful lot of unnecessary deco.
Example:
Either my 250' or my 200' Excel sheet contains a "model" for that depth and the stated range. Works fine if you stay close to the given depth and time range. When something works people start to trust it for ever greater things. Per Storker, you don't EVER use an approximation outside of the parameters that it was designed for.
Example:
My sheets work great for either 200 or 250 feet. They were designed for that. You get great numbers in and around the narrow area that is modeled. The model also shows the "lumpiness" expected in something created from observation (Navy Table 5) Look at the differences.
Wow, nice fit. This can be trusted!") (that feeling is easily cured)
(that feeling is easily cured)
Just enter a dive to 20 feet for 10 minutes in either of the yellow boxes (calculator) and look at the required deco...
Example:
Either my 250' or my 200' Excel sheet contains a "model" for that depth and the stated range. Works fine if you stay close to the given depth and time range. When something works people start to trust it for ever greater things. Per Storker, you don't EVER use an approximation outside of the parameters that it was designed for.
Example:
My sheets work great for either 200 or 250 feet. They were designed for that. You get great numbers in and around the narrow area that is modeled. The model also shows the "lumpiness" expected in something created from observation (Navy Table 5) Look at the differences.
Wow, nice fit. This can be trusted!
(that feeling is easily cured)Just enter a dive to 20 feet for 10 minutes in either of the yellow boxes (calculator) and look at the required deco...